Long before ChatGPT entered our daily lives, I was exploring the use of AI/ML in Cybersecurity Threat Detection, UEBA, Fraud Detection and AI Data/Model protection. I firmly believe that AI has a significant role to play in enhancing people’s lives through productivity and safety. More to come…
Here is what ChatGPT had to say about the subject.
Artificial Intelligence (AI) in cybersecurity is a rapidly evolving field that leverages machine learning, deep learning, and other AI techniques to enhance the security of computer systems, networks, and data. AI is playing an increasingly crucial role in cybersecurity due to the growing complexity of cyber threats and the need for faster and more proactive responses. Here are key points about AI in cybersecurity:
Threat Detection: AI helps in the early detection of security threats, including malware, ransomware, phishing attacks, and insider threats. Machine learning algorithms analyze vast amounts of data to identify patterns and anomalies that might go unnoticed by traditional security systems.
Behavior Analysis: AI can monitor and analyze the behavior of users and devices within a network to identify unusual or malicious activities. It can establish a baseline of “normal” behavior and then alert security teams when deviations occur.
Adaptive Security: AI systems can adapt to evolving threats and update their algorithms and heuristics to remain effective in detecting new attack vectors and tactics.
Automated Response: AI can automatically respond to security incidents by isolating compromised devices, blocking malicious traffic, or initiating other protective measures, reducing response times and minimizing potential damage.
Zero-Day Exploits: AI can identify zero-day vulnerabilities and potential exploit techniques by analyzing code, network traffic, or user behavior, enabling organizations to take preventive actions.
User and Entity Behavior Analytics (UEBA): AI-based UEBA systems examine patterns of user and entity behavior to identify insider threats, credential theft, and other malicious activities. They can correlate data from various sources to provide a holistic view of user activities.
Threat Intelligence: AI can process and analyze massive volumes of threat intelligence data from various sources to provide real-time insights and predictions about emerging threats.
Natural Language Processing (NLP): NLP is used to analyze and understand unstructured data, such as text in emails or documents, to detect phishing attempts or other social engineering attacks.
Security Orchestration and Automation: AI can automate incident response processes, such as alert triage and remediation, freeing up security teams to focus on more complex tasks.
Deep Learning: Deep learning techniques, such as neural networks, are employed for advanced threat detection and classification. They can identify complex, previously unseen threats based on learned patterns.
Challenges: While AI is a powerful tool in cybersecurity, it’s not without challenges. Adversaries can use AI to create more sophisticated attacks, and AI systems themselves need to be protected from manipulation.
AI in cybersecurity is a critical component in addressing the ever-evolving and increasingly sophisticated landscape of cyber threats. It complements traditional security measures and provides organizations with the capability to detect and respond to threats more effectively and in real time. As cyber threats continue to evolve, AI is expected to play an even more significant role in securing digital assets and data.
In the conclusion of my last post Data Leak Visibility, I mentioned that Elasticsearch, Logstash and Kibana (ELK) stack can be used to aggregate data from multiple osquery agents and can be used to analyze the data. This post will provide a high level view of what was done to connect the agents to the ELK stack and how I was able to not only analyze the data, but also to create very useful visualizations of the data from multiple sources.
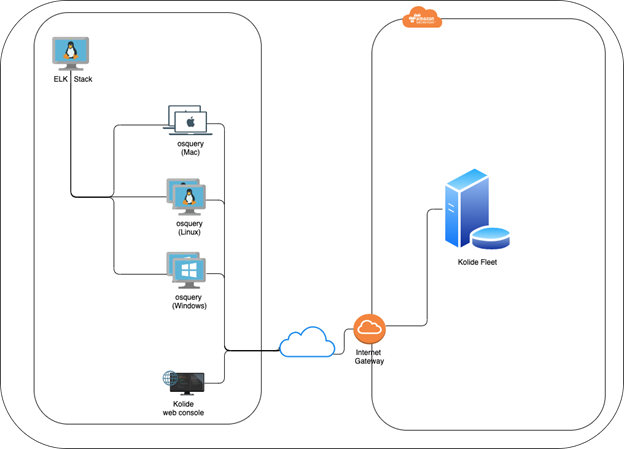
Let us start with a high-level view of what my deployment looks like.
I have a Kolide fleet manager setup in AWS cloud as described in my previous post Data Leak Visibility. There are multiple ways to deploy the ELK stack; a) It can be deployed as a docker container locally or in the cloud; b) AWS provides a fully managed Elasticsearch service; or c) Local Linux (CentOS or Ubuntu) machine with an ELK stack. I chose option (c), but had to ensure that the machine had a static IP assigned to it. In a typical enterprise deployment, option (b) would be a good choice as it is a fully managed service, albeit at a higher cost. In fact, both for fleet manager and ELK stack, cloud deployment is the way to go, since this provides full visibility into users within the enterprise and those not connected to the enterprise network i.e. those working from home.
Shipping Endpoint Data to ELK
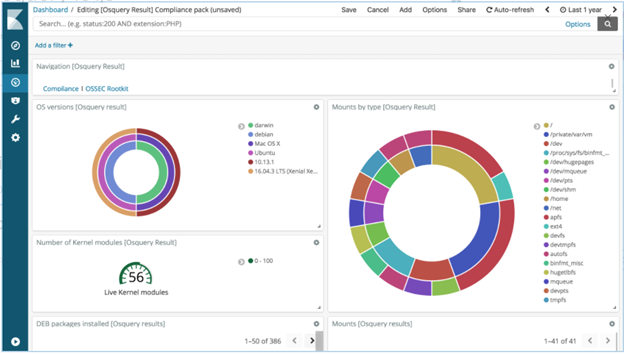
There are a number of ways to ship the data that is collected by osquery to the ELK stack as described in Aggregating Logs. Another way is to use Filebeat directly to read the osquery results and ship the data to the ELK stack. I chose the Filebeat method because it allows Kibana to display a pre-canned dashboard for an osquery pack named “it-compliance”. The dashboard provides visibility into the managed fleet Operating Systems (currently Darwin and Linux only), mount points and installed DEB packages.
Querying data using Kibana
Once Elasticsearch is set up with osquery and Filebeat running, it is easy to analyze the data being ingested into your Elasticsearch stack using Kibana. Typically, in an enterprise environment one can enable osquery packs for specific needs (compliance, vulnerability management, monitoring, etc.), but I would recommend not hardcoding the osquery configuration using local configuration file and instead using Kolide fleet manager to deploy configuration and packs. The Kolide fleet manager provides an intuitive UI to create and test the queries.
There is also a great tool called fleetctl created by the authors of Kolide fleet, to manage the manager configuration and for conversion of osquery packs. This was very useful for my setup.
Once the query results are validated, they can be deployed either via the fleetctl tool or the UI to deploy them as packs directly from the manager. When creating the pack, it requires the previously created query, the interval (how often to run the query), the platform(s) and the type of logging.
As an example, I created and deployed an osquery pack to gather results for the printed documents from all my macOS machines:
Query: SELECT * FROM cups_jobs
Interval: 3600
Minimum version: All
Logging: Differential (Ignore Removals)
Once the pack is deployed and runs, osquery will write out the results of the query to osquery.results.log file. Filebeat will pick up the results and ship them to ELK stack which are then ingested by Elasticsearch. At this point it is possible to start analyzing the data.
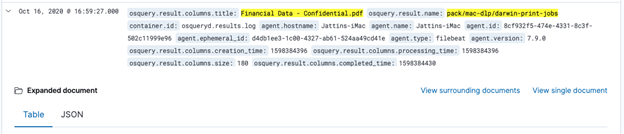
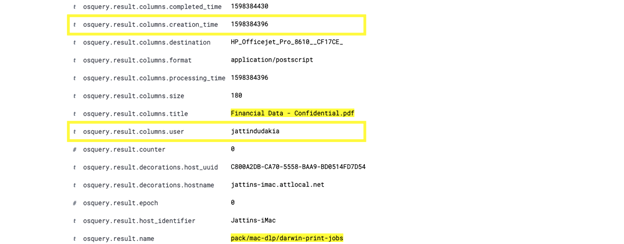
As an example, I ran the following query in Kibana to identify if a specific confidential document was ever printed by any users.
osquery.result.name : "pack/mac-dlp/darwin-print-jobs" and osquery.result.columns.title: "Financial Data - Confidential.pdf"
As shown below, I was able to identify which user printed a confidential document and when it was printed:
Expanding the result, it is possible to see which user printed this document and the date/time in Epoch (converted: Tuesday, August 25, 2020 12:40:30 PM GMT-07:00 DST):
Note: Filebeat configuration is set up to prefix all results with a “osquery.result” tag, so when creating a search query in Kibana, as one types “osquery.result”, it will list all available tables and fields associated with osquery.
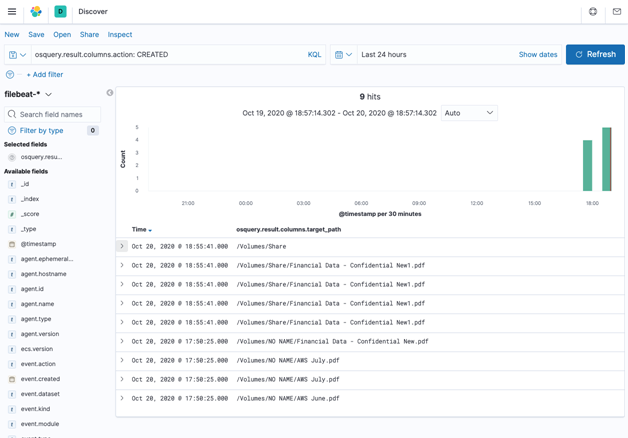
Here is another example of identifying if a particular confidential document was copied to USB or a file share.
Visualizing Data using Kibana
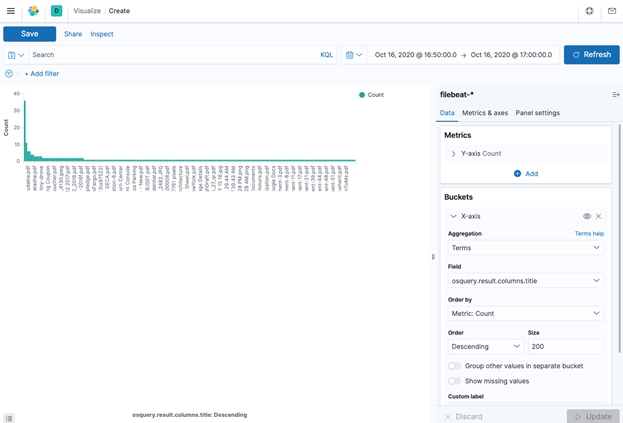
Kibana includes the ability for users to create visualization of the data, which can be effective for data analysis. In my case, I wanted to visualize what documents have been printed from all the machines in my fleet. The following shows the count of each printed document:
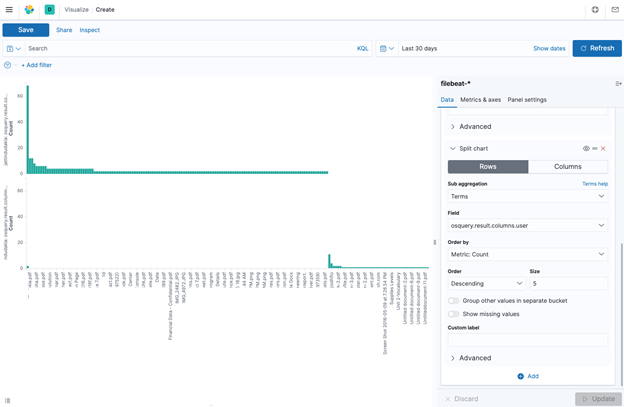
In addition, if one wanted to visualize the users who have printed the documents, one could create a Split chart by rows with a sub aggregation on the term “osquery.result.column.user”. This will display a bar graph for each user and what documents they printed as shown below:
Conclusion
The combination of osquery, Kolide fleet manager and ELK stack presents a very powerful set of tools in an arsenal of Cyber security tools needed to protect against potential threats and Data Leak Information (DLI).
Security vendors are selling similar tools at exorbitant costs and can be cost prohibitive for small to medium size businesses (SMB) with limited IT budgets. While the Cyber security threats continue to grow with the increased risk due to employees working from home, utilizing the tools described here would be invaluable for most organizations.
In my last post Limitations of Data Loss Prevention Solution, in the conclusion, I mentioned that osquery is a formidable open source agent for endpoint visibility on most common operating systems such as Windows, macOS and Linux. It can provide an audit trail for user actions. It exposes operating system and events on the system as a high-performance relational database. The osquery agent can be deployed as a standalone package which can run as an application or daemon/service. Typically, in an enterprise deployment you would want it to run as a daemon on *nix machine or a SYSTEM level service on windows.
Having an agent on an endpoint is obviously not enough, you also need something to manage those agents. This is where open source really shines. There is an open source manager just for this purpose called Kolide Fleet, which connects agents and allows admin to query any agent(s) for specific information from their host(s). Because osquery natively exposes the OS information as a relational database, there are many tables and each table can be queried using SQL query directly from the Kolide Fleet manager.
There are number of ways to deploy the Kolide Fleet manager, such as an on-prem server running the Kolide stack or a cloud deployment with instances running the Kolide stack components. For most enterprises, a cloud deployment would be a cost-effective and expedient way to try out Kolide Fleet manager and learn the capabilities for osquery. The developers of osquery and Kolide Fleet (one and the same) have done excellent work in making both open source and provide solid documentation. In addition to this, there is a large open source community supporting both. Many large enterprises continue to add additional features and functionality, which makes it a viable solution for endpoint visibility for small or large enterprise.
Endpoint Fleet Management
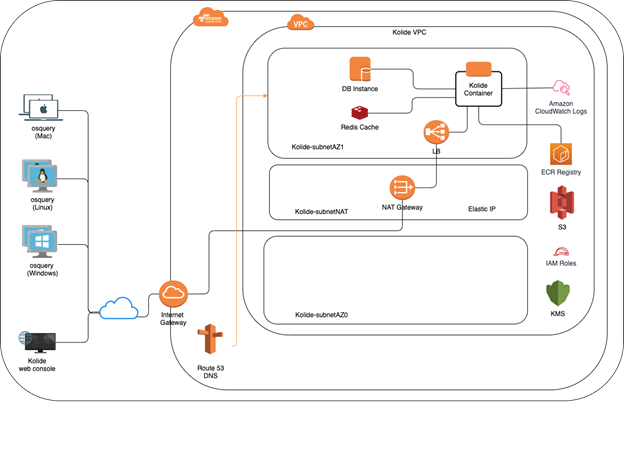
I wanted to demonstrate the power of cloud deployment, the ease with which I was able to get my system up and running and put my AWS learning to good use. I created the architecture shown below for a cloud deployment of Kolide Fleet Manager.
The magic of infrastructure as code is awesome!
I was able to create the complete system using a few YAML templates in AWS Cloud Formation. I can create and destroy the complete infrastructure at will within a few minutes.
The interesting challenge in creating this architecture was using a domain I purchased through GoDaddy and route traffic using AWS Route 53 DNS to my Kolide stack.
I also felt that somehow AWS should provide the capability to create the infrastructure diagram automatically based on the connected components. Hopefully, an AWS product manager reads this blog.
Endpoints Visibility using osquery
I created four endpoints in my home network (Windows 10 VM, Linux CentOS 7.2 VM, macOS 10.15 and macOS 10.14) installed osquery on them and connected them to my cloud deployment. The reason I wanted to create two macOS endpoints was to see how well osquery works on macOS 10.15. One of the challenges for such agents is that Apple has introduced significant security restrictions for applications, and I wanted to observe if there were any potential issues running osquery on macOS 10.15. I did not observe any issues in my tests.
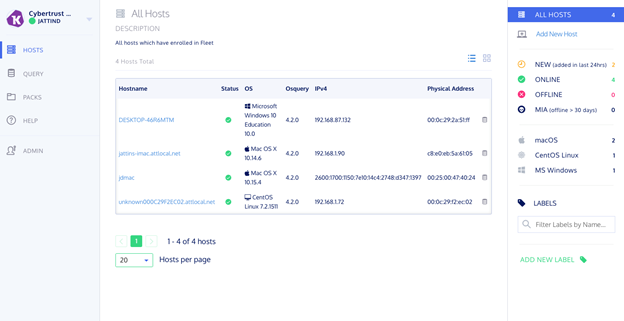
As it can be seen below the home page displays the endpoint machines.
When the endpoints are disconnected, their status will change from online (green) to offline (red). As more endpoints are added they will show up as new hosts in the home page. It also displays the OS type and versions which is very useful if you need to ensure compliance.
Data Leak Information
I will not go into each of the tables and queries supported by osquery as the documentation provided by osquery docs does an excellent job, instead I wanted to focus on the usability of such a system in a typical enterprise environment for Data Leak Information (DLI). There are three use cases I was able to easily verify for DLI on macOS:
Capture information on documents printed from a host. On macOS, the printing uses CUPS (Common Unix Printing System) and osquery has a CUPS table which will capture any documents being printed from that host. This indeed is very helpful where one needs to capture potential data theft.
Using a simple SQL query shown below, I was able to a get a complete list of every document ever printed from my machine (all records dating back to 2014 and well before I installed osquery).
SELECT * FROM cups_jobs;
The image above is from the exported csv file from Kolide Manager and shows the various times in Epoch time. The Epoch time (1598384396) translated to human readable date/time for the Financial Data – Confidential.pdf is Tuesday, August 25, 2020 12:39:56 PM GMT-07:00 DST. It also shows the username of the individual who printed the document.
Capture information on documents being copied to a USB device on a macOS host
Capture information on documents being copied to a share drive from a macOS host
Using the following somewhat more complex SQL query shown below, I was able to a get information on documents copied to both USB and network share drives.
SELECT action, file_events.uid, users.username, SUBSTR(target_path, 1) AS path, SUBSTR(md5, 0, 8) AS hash, time FROM file_events INNER JOIN users ON file_events.uid=users.uid WHERE sha1 <> '' AND target_path NOT LIKE '%DS_Store';
The results of running the query locally will show all files copied by a user to either a USB or a share drive as shown below.
Conclusions
There are several large enterprises using osquery for different use cases such as monitoring, incident response, IT compliance and vulnerability management. For each of these use cases, osquey supports a configuration through packs (groups of predefined quires, which run on a pre-defined schedule). I have presented yet another use case which osquery can easily support for monitoring DLI.
In a typical enterprise environment, it is unrealistic to query each of the hosts, but the capabilities built into osquery allow it to be connected to an ELK stack or to AWS Kinesis. The data gathered from all the hosts can easily be analyzed for such leaks. This makes an osquery based fleet very powerful for monitoring systems across the whole enterprise.
Data Loss Prevention (DLP) solutions and their Limitations
Have you ever attempted to balance rocks?
Stacking rocks on top of each other requires a great deal of skill, patience, and it is just a matter of time before the pile will collapse. The slightest gust of wind or an incorrect movement of the hand when placing one rock on top of another, and you will have to start all over again.
You are probably wondering what stacking rocks has to do with Cybersecurity and more specifically Data Loss Prevention. Well, they are very similar in nature! Cybersecurity requires specialized knowledge of computer science (kernel level reverse engineering), in-depth knowledge of potential exfiltration vectors, and a disciplined software development process to create the DLP solutions. Even with all the above, one knows the next version of the Operating System (OS) or the next version of an Application will likely break the solution.
Imagine an endpoint agent which needs to guard against potential data leaks from many different egress channels and that each channel presents a unique way to leak the data.
Endpoint Agent guarding against potential data leaks!
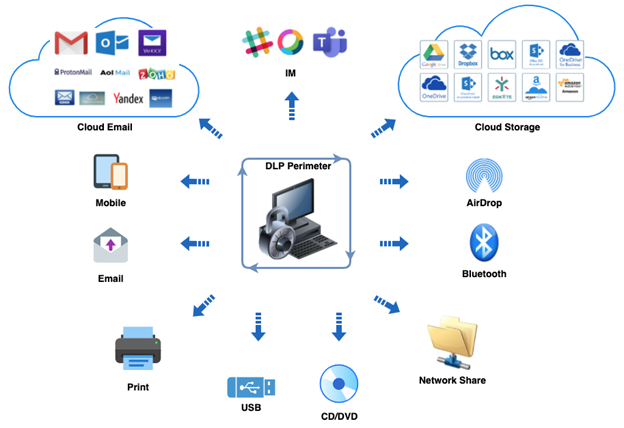
Egress channels can take many forms as shown in the diagram below. Also, over time, OS vendors have introduced new channels, such as AirDrop and Bluetooth. If you are using a legacy DLP product, check their supported list of channels. Do they protect data exfiltration over AirDrop or Bluetooth channels?
The egress channels are not just the physical outlets from the machine, but also the application protocols used to transfer data over them. As an example, the network port (Wi-Fi or Ethernet port), essentially represents two egress channels, but the issue is compounded by the fact that higher level application protocols, which use these ports, can be 10x. This results in significantly more egress channels. Each one needs to be manned 24/7 to prevent escape.
While one can try to normalize the data from these channels to detect data theft, the protocols often make it impossible to have full visibility into all the data.
Data Rules
Let us discuss Data rules. DLP products allow you to define rules around the specifics of the data which you are trying to protect. This can range anywhere from Personal Identifiable Information (PII) to Personal Health Information (PHI), Payment Card Industry Data Security Standards (PCI -DSS), and custom data. The essence of DLP is to know the data you are trying to protect from leaking and to detect when it is being leaked. It can be in the form of a string such as a credit card number, social security number or a hash value of the data.
Say you define a custom rule to protect a document which has the word “keepmesafe”. When seen by a DLP agent, it is an indicator that a document containing such a word cannot leave its protected perimeter. There are many subtle ways to modify this data before sending it out and then to re-construct the data outside in the desired form.
How would one change the data so that it is undetectable by a DLP agent? I will leave this to your imagination, but it does not take much to change “keepmesafe” to “keep*me*safe” or “keep-me-safe”, possibly even breaking it up into separate words before sending it.
OS/Application Impact
Apple, in every release of macOS, has introduced changes to the operating system and their applications, such as Apple Mail and Safari. These changes have resulted in breaking DLP functionality. The core technology used by major DLP products is to inject code into an application, which then allows the endpoint agent to monitor the traffic. Apple introduced System Integrity Protection (SIP), which prevents code injection.
Both Microsoft and Apple are sandboxing their applications to prevent code injection or any other form of code modifications. Most recently Microsoft announced that they will disable injection based Outlook Mail plugins (Disable MS Outlook Injection). This impacts DLP security vendors as they will not have visibility into Outlook Email channel.
What are the security vendors doing to get around such limitations?
They try to find other ways to get visibility into the egress channels. When Apple blocked code injection into Safari as part of the Mojave release, it was a major blow to the security vendors as they lost visibility into all egress data from the browser. There are a number of ways to solve this but only partially. Some of these ways are to (a) create a browser extension which can capture POST requests or to (b) perform a Man-In-The-Middle (MITM).
(a) Browser extensions present significant limitations. Not all POST data is visible to the extension, and they often depend on the APIs supported by the browser. Additionally, browser extensions can only function under certain conditions and often break compatibility due to other browser extensions. Management of browser extensions becomes a challenge if you are using an enterprise product such as GSuite, because the security vendor installs the extension outside the control of GSuite. Most importantly, browser extensions are rendered useless in private/incognito mode. There are other limitations, such as how traffic from web sockets is not visible to the extension due to API limitations.
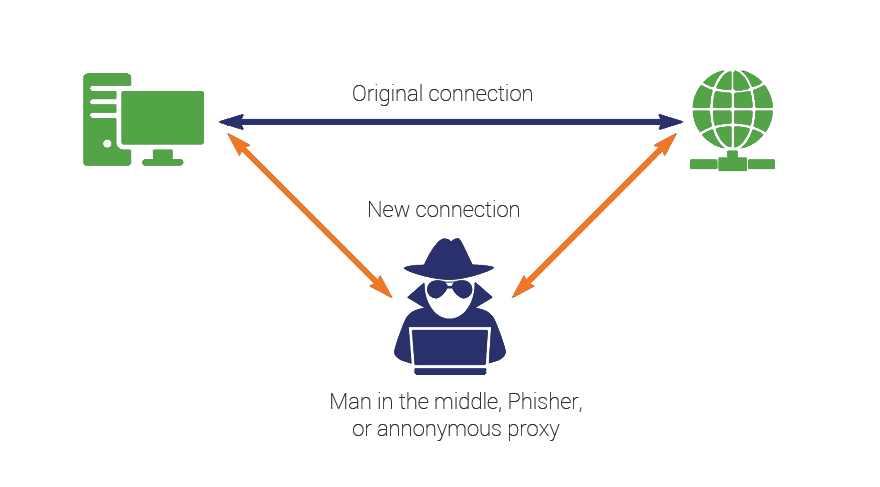
(b) The following diagram depicts (MITM). Basically, the agent breaks the original connections and acts as the middleman to relay traffic between the endpoint application and the destination.
While this provides visibility into all the SSL egress traffic, it has also a significant downfall. Your data privacy is compromised. The DLP agent is potentially listening in on your “private” connection.
What about cloud storage applications?
There are two forms of egress channels for cloud storage applications (i.e. OneDrive, Google Drive, Dropbox, Box, and others) : 1) access via the browser; and 2) access via a native application. Both present challenges for legacy DLP solutions. We have already discussed some of the browser challenges, but native apps present a different challenge; they use protocols and features that often completely sidestep the DLP agent, such as (Document collaboration).
What about cloud email services such as Gmail or Yahoo Mail?
Data can be leaked either in the email body and/or as an attachment to the email. Since this channel uses a browser, the DLP vendor must support the browser and its specific version. Often, even when the DLP vendor claim support for a given browser, a new version of the browser may break their APIs used to intercept the traffic. Browser vendors such as Google, Mozilla and Safari release updates every 4-6 weeks. The rate of potential breakage is high.
The DLP agent can often handle the content within the email body well, but attachments present a different problem. If the DLP agent detects a false positive on a legitimate email with attachments, the user will start seeing popups by the DLP agent blocking the email. This is because email providers, such as Gmail, will continually retry to sync the email. Imagine the impact on the productivity in a Fortune 500 enterprise environment.
Conclusions
Until now, DLP vendors have relied on reverse engineering and proprietary API access to get visibility into data traffic. OS vendors need to start playing a significant part in enabling access to documented APIs, which do not break the DLP on every new release of their OS. Apple has already begun this journey through their post Catalina support with the Endpoint Security & System Extensions. Application vendors will need to play a bigger role in supporting documented APIs. As you can imagine, the timeline for achieving collaboration between OS vendors, Application vendors, and Cybersecurity vendors is a long way off.
In the near term, instead of depending solely on the DLP vendor to provide an audit trail for the data leak, enterprises can deploy other forms of security to get visibility into their endpoints. There are some serious open source contenders (osquery), which allow you to get full visibility into your endpoints and specifically allow you to get an audit trail. As an example, osquery supports File Integrity Monitoring (FIM), which combined with its hardware monitoring capability can be used to capture USB file transfers. Many large enterprises (Netflix, Facebook, Airbnb, and Akamai) are using osquery for monitoring their fleet. It is also the core for several other security products provided by major vendors in the EDR space.
In conclusion, know the limitations of the product you are using and carefully inspect the support matrix of the product. There is nothing worse than a false sense of security.